這次來寫點不一樣的東西,保證很多人看不懂甚至看不下去,因為要弄懂這個東西需要有很好的電腦觀念和數學觀念。但是為什麼要寫這個東西呢,因為微軟的資料庫(Microsoft SQL Server 2005)裡面的資料挖掘就是利用這樣的機制所設計出來的,能夠了解這個原理會讓資料庫管理人員能夠正確的應用這項技術。
漠哥研究這個東西實際上已經有十幾年了,但是數學本身并不是很好,而且所能夠找到的參考書籍和論文大多是胡說八道,或者是只寫了結果要用某某微積分方法,卻沒有說明為什麼,對於我這種只能記原理的人來說非常的痛苦,因此進度緩慢,也不敢說有什麽心得。也順便抱怨一下,以前學校也學過微積分,但是卻沒有人告訴我那些東西可以用在什麼地方,讓我從三角函數小老師一下子變成了數學白癡,幸好生活中用到微積分的地方不多,不然真的活不下去了。
什麼是類神經網路
類神經網路是一種使用數學方法,透過電腦的快速計算能力,而使得電腦能夠具有推論結果能力的人工智慧機器。它必須經過學習的過程才能夠擁有推論能力,也就是說要有人告訴它什麼樣的情況會得到什麼樣的結果,你告訴它越多正確的範例(狀況+結果)它就能夠正確的回答你,甚至於沒有學過的範例,它也能告訴你可能的結果。
它還有一個好處,就是類神經網路并不會因為資料的大量成長而快速長大,而是一個固定的大小,也就是說除非你給的狀況或者結果的數量改變,否則并不需要變動網路架構,這使得對於記憶體上的需求變得可以預測,例如類神經網路最好的應用--手寫辨識,它可以讓手寫辨識裝置的記憶體空間是可以預測的,因為字就那麼多,而手寫板的感應點也是固定的,所以在設計硬體的時候就能夠把記憶體空間固定下來。
對於這樣的作用能力,如果使用資料庫來做,那就只能夠建立一個龐大的資料庫,讓使用者自己去查,而由於資料庫過於龐大,使用者要從裡面找到正確的答案將是非常的困難,例如客戶關係管理(CRM)裡面的許多環節就是極度需要能夠從龐大的資料庫中快速的找到少量而正確的一個例子。
簡單的類神經網路架構
因為人工智慧在國外的研究其實蠻多的,經過了這麼久的時間自然演化出許許多多的網路架構去解決不同的問題以及速度上的改進。但是我們只看最簡單的一種,了解原理比什麼都重要。
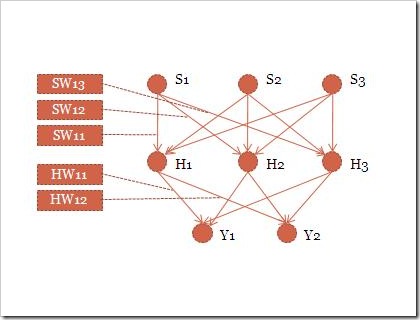
這個架構裡面包含了三層,S輸入層,H隱藏層,Y輸出層,每一層的圓點代表一個神經元,輸入層就是讓你把狀況告訴它,換句話說就是把手寫版的每一個點對應到每一個輸入層。隱藏層這裡只有一層,對於複雜的網路建議使用多個隱藏層,這樣網路才能記憶更多的狀況。而輸出層就是結果,如果以手寫系統來看就是中文內碼的每一個位元。
而每一層之間的連線叫做神經鏈,是主要記憶與推論的地方,每一個神經鏈都是一個浮點數,經過層層的計算就可以得到最後的輸出結果。舉例而言
H1=S1*SW11+S2*SW21+S3*SW31
也就是說H1就是把所有上一層的神經元的值乘以神經鏈加總起來的結果,輸出層也是相同的原理。用手寫辨識為例子,請配合著圖看S1這個神經元比較容易了解,就是每一個手寫板的感應點都會透過神經鏈影響每一個隱藏層,進而影響每一個中文內碼的每一個位元。
神經網路的修正
一開始的神經網路的神經鏈通常都是用亂數去產生的,所以輸出的結果肯定會和標準值(V)是有誤差的,所以就需要對網路做修正。我這裡不談很深的數學,只用原理來解釋。因為有誤差所以就必須要根據誤差值來修正,可以知道
輸出層的誤差值(YD)=標準值(V)-輸出值(Y)
而每一個神經鏈要修正的誤差值簡單來看就是看有多少的神經鏈連接到這個神經元,以上圖的Y1來看就是有三個神經鏈連過來,所以每一個神經鏈只要修正1/3就夠了。但是單單這樣每一個神經鏈都會修正同樣的值,必須要再乘以上一層的輸出值才是每一個神經鏈要修正的值。這樣來看也才會符合輸入影響輸出的定義。
而隱藏層因為沒有標準值,它的誤差值必須由下一層的誤差值來提供,也就是
隱藏層的誤差值(HD)=下層所有的 (誤差值(YD) * 神經鏈(W))
網路學習循環
通常問題與答案如果以數學圖表來看,它并不會是一個很漂亮的曲綫,也就是說你不可能一次就修正到最接近的輸出值,而是需要多次的修正。而且也沒有辦法以誤差值的收斂來看是不是應該要終止學習,因為輸出值可能現在已經掉到第一個谷底,而標準值卻在另一個谷底,而且爲了避免谷口的寬度過小,太大的修正值可能會直接跳過可能的正確值,所以通常會賦予一個學習速率值,也就是讓每一個修正值去乘以學習速率,讓每一次的修正值變小,以減少誤差。
結論
類神經網路的確可以解決很多一般電腦程式所不能解決的問題,並且能夠更加聰明的提供問題的解答,例如很早以前漠哥做的電路板輔助量測檢修系統、股票指數預測、天氣預測、手寫辨識許許多多的應用,知識管理+客戶關係管理是最新的應用實例。
附注
坊間很多論文或書籍會用一個輸出值去代表許多的輸出結果,例如1=A,2=B,3=C這樣的設計是完全錯誤的,應該要讓每一個輸出值代表一個意義。這樣說吧,你怎麼知道B一定是在A後面,如果說它的隱藏層夠多,能夠容納更多更複雜的狀況我還能夠接受。但是如果用多個輸出值來代表,那就可以看成是每一種結果值的幾率。
這篇文章只是談它的原理,運算公式并不是這麼單純,如果照著做會出現許多問題,例如運算過程產生溢位或者是收斂速度太慢,不過精神都已經提到了。






3 則留言:
寫的非常清楚
感謝 ^^
我看了後還滿有興趣的,不過對於詳細回饋方面的數學式 不知是否能在詳細說明 或是介紹我看其他的相關書籍 期待您下一次發文
所以隱藏層(H)是相對於輸入層(S)的數量(單一層的各數)嗎?還是類似神經線,經誤差修正後會刪減。
增加隱藏層的層數意即可以增加考慮的條健,那再增加層數方面大概要怎麼設計??我的意思是如果以手寫板為例子的話,什麼情況下需要增加隱藏層的層數以及決定他的個數呢?
感謝分享。
張貼留言